ch 04. Process Scheduling
Written by Sangchul, Lee
content
- Summary of book
- Linux kernel (4.11.x) implementation analysis
Summary of book
The process scheduler decides which process runs, when, and for how long. By deciding which process runs next, the scheduler is responsible for best utilizing the system and giving users the impression that multiple processes are executing simultaneously.
preemptive & cooperative
In preemptive multitasking, the scheduler decides when a process is to cease running and a new process is to begin running. The act of involuntarily suspending a running process is called preemption.
timeslice : The time a process runs before it is preempted.
In cooperative multitasking, a process does not stop running until it voluntary decides to do so. The act of a process voluntarily suspending itself is called yeilding.
Problem of cooperative multitasking :
The scheduler cannot make global decisions regarding how long processes run. Then, processes can monopolize the processor for longer than the user desires.
I/O-Bound & Processor-Bound
- I/O-bound process is runnable only short durations, because it eventually blocks waiting on more I/O.
- Processor-bound processes tend to run until they are preempted because they do not block on I/O requests very often.
The scheduling policy in a system must attempt to satisfy two conflicting goals :
- Fast process response time (low latency).
- Maximal system utilization (high throughput).
while not compromising fairness.
Process Priority
nice value : a number from -20 to +19 with a default of 0. Larger nice values correspond to a lower priority — being "nice" to the other processes on the system. Nice values are the standard priority range used in all Unix systems.
In Mac OS X, the nice value is a control over the absolute timeslice allotted to a process.
In Linux, it is a control over the proportion of timeslice. (CFS)
real-time priority : default range from 0 to 99. Higher real-time priority values correspond to a greater priority. All real-time processes are at a higher priority than normal processes.
Where is nice value saved?
In
task_struct, there is no nice property alone. Inprioproperty(0-139), nice value is saved with real-time priority, but in this case, smaller number indicate higher priority.rt_priorityindicate real-time priority(0-99) which higher number is higher priority.

Timeslice
The timeslice (quantum) is the numeric value that represents how long a task can run until it is preempted.
Too long a timeslice causes the system to have poor interactive performance.
Too short a timeslice causes significant amounts of processor time to be wasted on the overhead of switching processes.
I/O-bound processes do not need longer timeslices (although they do like to run often).
Processor-bound processes crave long timeslices (to keep their cache hot).
CFS scheduler assigns processes a proportion of the processor, therefore, the amount of processor time (timeslice) that a process receives is a function of the load of the system. The nice value acts as a weight, changing the proportion of the processor time each process receives.
Completely Fair scheduler
CFS is based on a simple concept : model process scheduling as if the system had an ideal, perfectly multitasking processor.
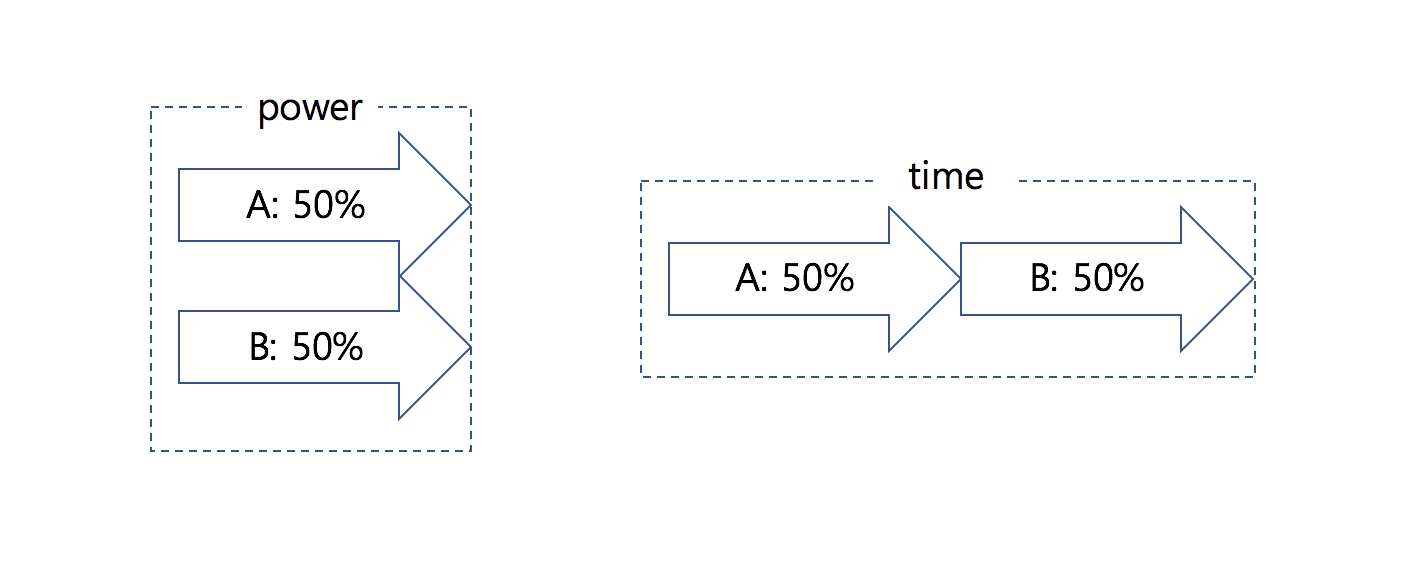
In an ideal, perfectly multitasking processor, we would run both processes simultaneously, each at 50% power. This model is called perfect multitasking. But in our real world, processor only can run one process at a moment. So, to make similar to perfect multitasking, each process receive 1/n of the processor's time, where n is the number of runnable processes.
There are several concept for CFS.
- CFS uses the nice value to weight the proportion of processor a process is to receive.
- To calculate the actual timeslice, CFS sets a target for its approximation of the "infinitely small" scheduling duration in perfect multitasking. This target is called the targeted latency. Smaller targets yield better interactivity and a closer approximation to perfect multitasking.
- CFS imposes a floor on the timeslice assigned to each process because if number of runnable tasks approaches infinity or targeted latency is too much small, this result in unacceptable switching costs. This floor is called the minimum granularity.
Linux kernel implementation analysis
1. Structures
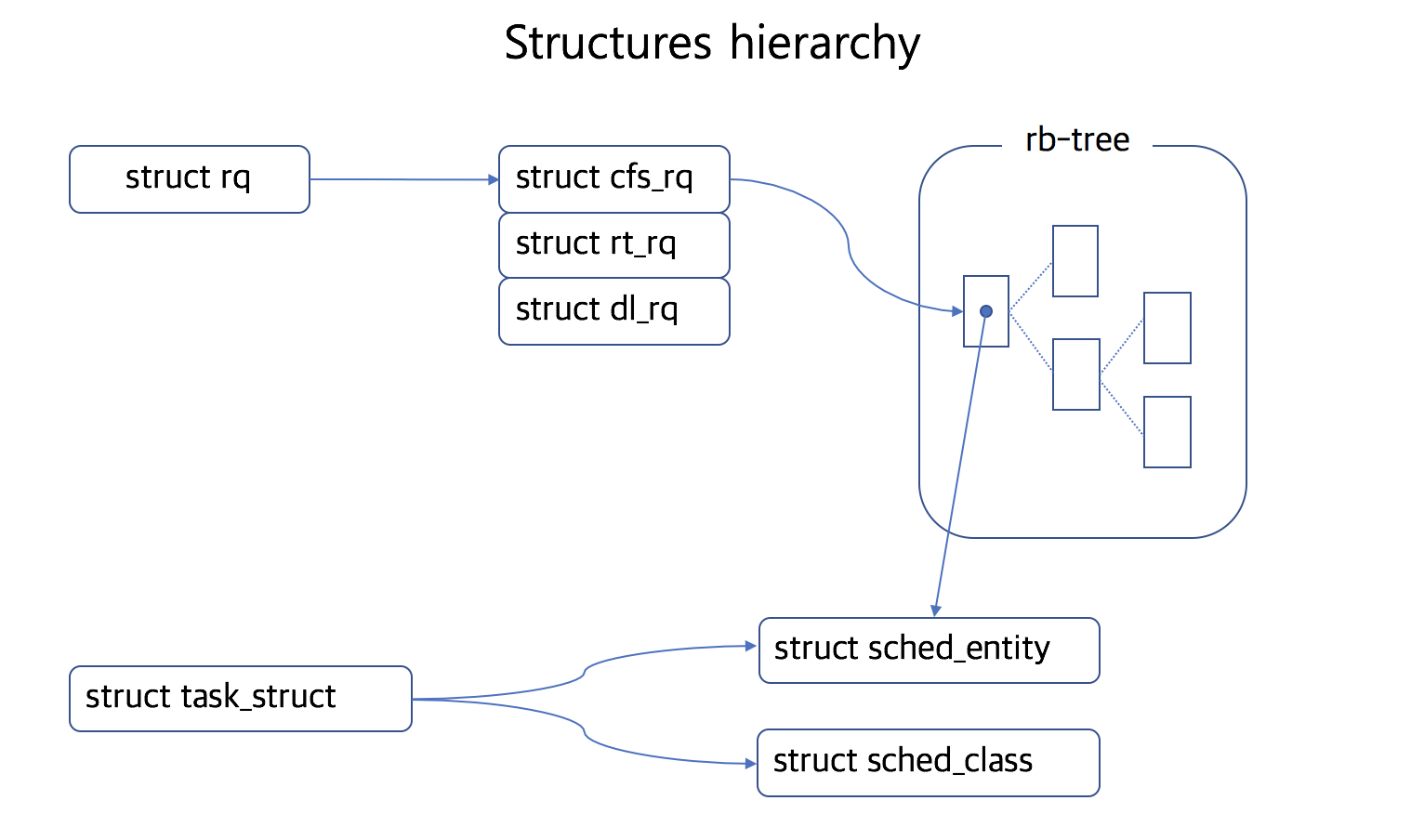
struct rq
struct rq {
struct cfs_rq cfs; // completely fair scheduler
struct rt_rq rt; // real-time scheduler
struct dl_rq dl; // deadline scheduler
}
- Per-CPU runqueue data structure.
- Each runqueue has schedulers, which are CFS, Real-time, and Deadline scheduler.
struct cfs_rq
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct rb_root tasks_timeline; // pointer to head of rb-tree
struct rb_node *rb_leftmost; // pointer to left most leaf of rb-tree (like cache)
}
CFS use rb-tree to manage tasks. Key for rb-tree is
vruntimewhich is member ofstruct sched_entity.
struct sched_entity
Schedule related things (like time it spend) are managed in sched_entity.
struct sched_entity {
// to account for how long a process has run and thus how much longer it ought to run
u64 vruntime;
// for load-balancing
struct load_weight load;
struct rb_node run_node;
}
The vruntime variable stores the virtual runtime of a process, which is the actual runtime (the amount of time spent running) normalized (or weighted) by the number of runnable processes. The virtual runtime is used to help us approximate the "ideal multitasking processor" that CFS is modeling.
struct task_struct
task_struct is process descriptor which save all the information about the task. (detail is in chapter 3)
struct task_struct {
struct thread_info thread_info;
int prio; // priority which include nice value (0-139)
unsigned int rt_priority; // real-time scheduler priority (0-99)
const struct sched_class *sched_class; // layer for different schedulers
struct sched_entity se; // to keep track of process accounting
struct sched_rt_entity rt;
struct sched_dl_entity dl;
unsigned int policy; // scheduling policy
cpumask_t cpus_allowed; // enforce hard processor affinity
pid_t pid;
}
struct sched_class
We have several different schedulers, so for regularity, we need an interface for schedulers to work properly. Inside sched_class, methods for scheduler (but which need different implementation) are saved as function pointers.
struct sched_class {
// Add task to the tree
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
// remove task from the tree (exit or blocked)
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
// call by timer interrupt
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
// call by timer interrupt to update info like vruntime
void (*update_curr) (struct rq *rq);
}
// initialize like this (for CFS)
const struct sched_class fair_sched_class = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.task_tick = task_tick_fair,
.update_curr = update_curr_fair,
};
2. Scheduling routines
There are two routines which are related to scheduling.
- First, routine to set
need_resched. - Second, routine that check
need_resched, pick up next task, and context switching.
Why do they divide like this? Because it is more easy and safe to context switch when return from interrupt handler. So mark it and check it before return from interrupt handler.
But, in kernel code, if it explicitly call schedule(), then it could just be rescheduled.
Here is the flow of routines.
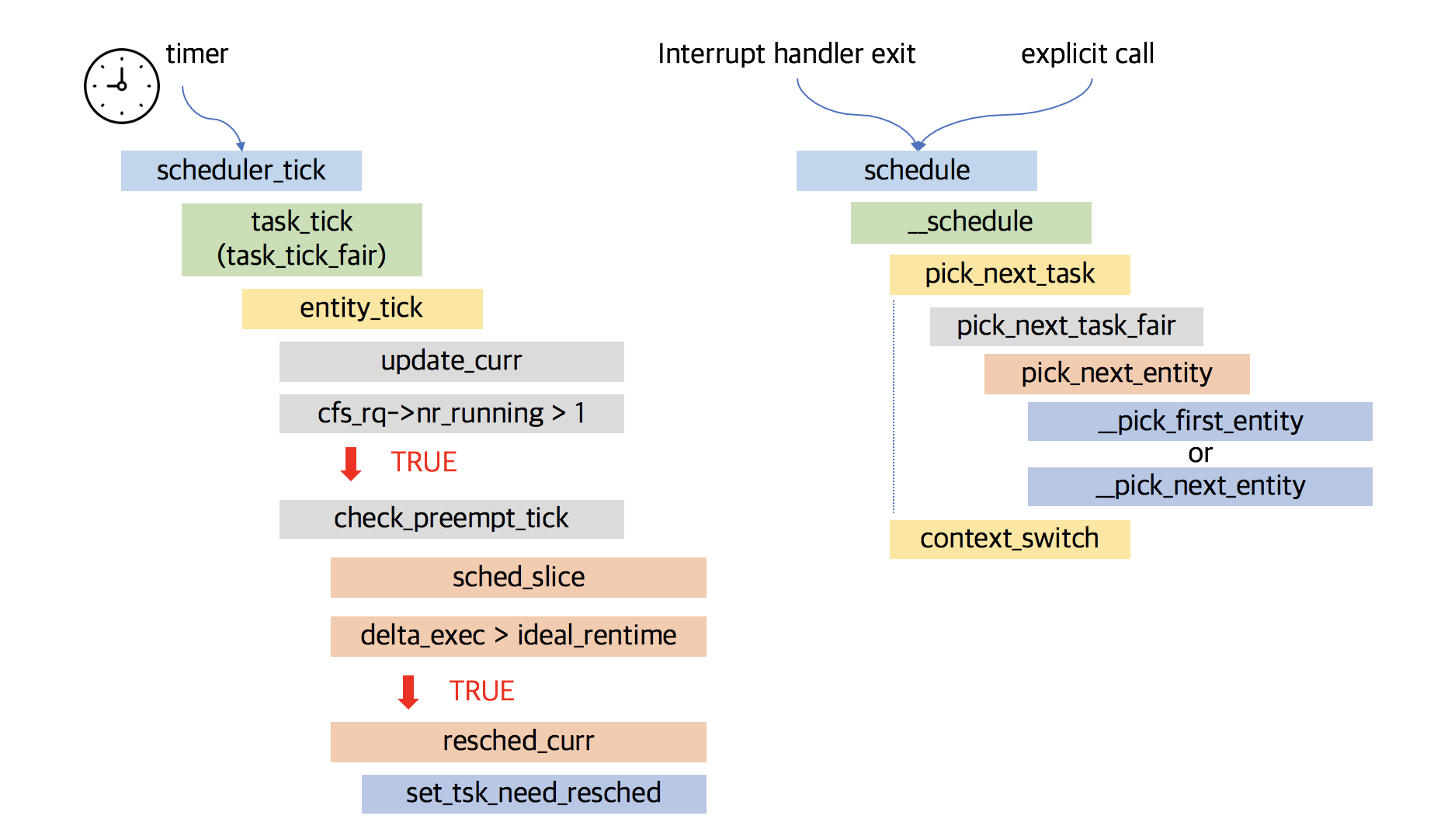
Let's see in details. (read comments carefully, and I deleted many lines of code that are seems to be not important to understand flow, does not mean that lines are not important)
First routine
1. Timer interrupt
Every time when timer interrupt occurs, timer interrupt handler is called. You can see more detail about timer interrupt in chapter 11. Every time when timer interrupt handler is called, handler call update_process_times function to charge one tick to the current process. Inside it, scheduler_tick is called.
2. scheduler_tick
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu); // get cpu's run queue
struct task_struct *curr = rq->curr; // get current task
sched_clock_tick(); // for unstable clock
raw_spin_lock(&rq->lock); // LOCK
update_rq_clock(rq); // update run-queue clock
curr->sched_class->task_tick(rq, curr, 0); // tack_tick callback (`task_tick_fair()`)
raw_spin_unlock(&rq->lock); // UNLOCK
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu); // check, is cpu in idle status
trigger_load_balance(rq); // SCHED_SOFTIRQ
#endif
rq_last_tick_reset(rq);
}
See curr->sched_class->task_tick(rq, curr, 0); this code carefully. You already saw sched_class which is an interface for scheduler methods. task_tick is now points to task_tick_fair for CFS.
3. task_tick (task_tick_fair)
/*
* scheduler tick hitting a task of our scheduling class:
*/
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued); // call entity_tick for each sched_entity
}
}
4. entity_tick
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
// Update run-time statistics of the 'current'.
update_curr(cfs_rq);
// nr_running: number of processes can run
// check recent task need to preempt
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
5. update_curr
There is no anymore __update_curr()
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
delta_exec = now - curr->exec_start; // calculate time process used
curr->sum_exec_runtime += delta_exec;
curr->vruntime += calc_delta_fair(delta_exec, curr); // calculate vruntime with weight
update_min_vruntime(cfs_rq);
}
This part of code update vruntime which is a key to choose next runnable process.
6. check_preempt_tick
/*
* Preempt the current task with a newly woken task if needed:
*/
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
// `ideal_runtime` is needed to compare with real exec time
ideal_runtime = sched_slice(cfs_rq, curr);
/*
* You already saw `sum_exec_runtime` in `update_curr()`
* `sum_exec_runtime` is the value which save CPU runtime in nano second.
* `delta_exec` will be timeslice(runtime after it scheduled) of this process
*/
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
// if it's true, then it already ran enough
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
clear_buddies(cfs_rq, curr);
return;
}
// if this process run less than minimum granularity, run again
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq); // return most left sched_entity (smallest vruntime)
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
7. reached_curr
/*
* resched_curr - mark rq's current task 'to be rescheduled now'.
*
* On UP this means the setting of the need_resched flag, on SMP it
* might also involve a cross-CPU call to trigger the scheduler on
* the target CPU.
*/
void resched_curr(struct rq *rq)
{
struct task_struct *curr = rq->curr;
int cpu;
if (test_tsk_need_resched(curr))
return;
cpu = cpu_of(rq);
if (cpu == smp_processor_id()) {
set_tsk_need_resched(curr); // set flag TIF_NEED_RESCHED
set_preempt_need_resched();
return;
}
}
Second routine
There are two ways (in large view) to go in scheduler.
- First, when an interrupt handler exits, before returning to kernel-space.
- Second, when a task in the kernel explicitly calls
schedule()
Let's look at the enterence of scheduler.
1. schedule
/**
* Main entry point into the process scheduler.
*
* This is the function that the rest of the kernel uses to invoke the process scheduler,
* deciding which process to run and then running it.
*
* `schedule()` is generic with respect to scheduler classes.
* That is, it finds the highest priority scheduler class with
* a runnable process and asks it what to run next.
*/
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
// enterence to main scheduler function (disable preempt before enter)
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched()); // if there is request to reschedule (check flag)
}
2. __schedule
Here is the comment for __schedule(). This comment is really important. You should read it.
/*
* __schedule() is the main scheduler function.
*
* The main means of driving the scheduler and thus entering this function are:
*
* 1. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2. TIF_NEED_RESCHED flag is checked on interrupt and userspace return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
*
* - If the kernel is preemptible (CONFIG_PREEMPT=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPT is not set)
* then at the next:
*
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
*
* WARNING: must be called with preemption disabled!
*/
Here is function code.
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
smp_mb__before_spinlock();
raw_spin_lock(&rq->lock);
rq_pin_lock(rq, &rf);
if (task_on_rq_queued(prev))
update_rq_clock(rq);
// pick_next_task: goes through each scheduler class, starting with the highest
// priority,and selects the highest priority process in the highest priority class.
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unpin_lock(rq, &rf);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}
There are two important function call.
pick_next_task()select task which should run next.context_switch()context switch to selected task.
3. pick_next_task
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those loose the
* opportunity to pull in more work from other CPUs.
*/
/*
* If the number of runnable processes is equal to the number of CFS runnable
* processes (which suggests that all runnable processes are provided by CFS).
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&
rq->nr_running == rq->cfs.h_nr_running)) {
// call `pick_next_task` method of CFS. (`pick_next_pick_fair`)
p = fair_sched_class.pick_next_task(rq, prev, rf);
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);
return p;
}
again:
/*
* Interates over each class in priority order, starting with the highest priority class.
* Each class implements the `pick_next_task()` function, which returns a pointer
* to its next runnable process or, if there is not one, NULL.
* CFS's implementation of `pick_next_task()` calls `pick_next_entity()`,
* which in turn calls the `__pick_first_entity()` function.
*/
for_each_class(class) {
// call `pick_next_task` method of specific scheduler.
p = class->pick_next_task(rq, prev, rf);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
/* The idle class should always have a runnable task: */
BUG();
}
4. pick_next_task_fair
static struct task_struct *
pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
again:
if (!cfs_rq->nr_running)
goto idle;
if (prev->sched_class != &fair_sched_class)
goto simple;
simple:
cfs_rq = &rq->cfs;
if (!cfs_rq->nr_running)
goto idle;
put_prev_task(rq, prev);
do {
// call `pick_next_entity` to pick next process
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
if (hrtick_enabled(rq))
hrtick_start_fair(rq, p);
return p;
idle:
new_tasks = idle_balance(rq, rf);
/*
* Because idle_balance() releases (and re-acquires) rq->lock, it is
* possible for any higher priority task to appear. In that case we
* must re-start the pick_next_entity() loop.
*/
if (new_tasks < 0)
return RETRY_TASK;
if (new_tasks > 0)
goto again;
return NULL;
}
5. pick_next_entity
/*
* Pick the next process, keeping these things in mind, in this order:
* 1) keep things fair between processes/task groups
* 2) pick the "next" process, since someone really wants that to run
* 3) pick the "last" process, for cache locality
* 4) do not run the "skip" process, if something else is available
*/
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*/
if (!left || (curr && entity_before(curr, left)))
left = curr;
se = left; /* ideally we run the leftmost entity */
/*
* Avoid running the skip buddy, if running something else can
* be done without getting too unfair.
*/
if (cfs_rq->skip == se) {
struct sched_entity *second;
if (se == curr) {
second = __pick_first_entity(cfs_rq); // pick most left one
} else {
second = __pick_next_entity(se); // pick next node
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
/*
* Prefer last buddy, try to return the CPU to a preempted task.
*/
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
/*
* Someone really wants this to run. If it's not unfair, run it.
*/
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
clear_buddies(cfs_rq, se);
return se;
}
struct sched_entity *__pick_first_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = cfs_rq->rb_leftmost; // get cached value
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node);
}
static struct sched_entity *__pick_next_entity(struct sched_entity *se)
{
struct rb_node *next = rb_next(&se->run_node);
if (!next)
return NULL;
return rb_entry(next, struct sched_entity, run_node);
}
Until now, we do hard works to select what to run next.
We can now execute context switch to run next task.
6. context_switch
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
struct mm_struct *mm, *oldmm;
prepare_task_switch(rq, prev, next);
mm = next->mm;
oldmm = prev->active_mm;
/*
* For paravirt, this is coupled with an exit in switch_to to
* combine the page table reload and the switch backend into
* one hypercall.
*/
arch_start_context_switch(prev);
if (!mm) {
next->active_mm = oldmm;
mmgrab(oldmm);
enter_lazy_tlb(oldmm, next);
} else
switch_mm_irqs_off(oldmm, mm, next);
if (!prev->mm) {
prev->active_mm = NULL;
rq->prev_mm = oldmm;
}
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
/*
* Since the runqueue lock will be released by the next
* task (which is an invalid locking op but in the case
* of the scheduler it's an obvious special-case), so we
* do an early lockdep release here:
*/
rq_unpin_lock(rq, rf);
spin_release(&rq->lock.dep_map, 1, _THIS_IP_);
/* Here we just switch the register state and the stack. */
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}