chapter 14 - The Block I/O Layer
Block Device hardware devices distinguished by the random access of fixed-size chunks of data
Anatomy of a Block Device
- sector
- block device 에서 접근할 수 있는 데이터의 최소 단위
- block
- 소프트웨어에서 접근할 수 있는 데이터의 논리적 최소 단위
- Although the physical device is addressable at the sector level, the kernel performs all disk operations in terms of blocks.
- device는 sector를 최소 단위로 하여 동작하지만, 커널은 모든 디스크 operation을 block 단위로 수행한다.
Buffers and Buffer Heads
- When a block is stored in memory(after a read or pending a write), it is stored in a buffer.
- Each buffer is associated with exactly one block.
- Because the kernel requires some associated control information to accompany the data, each buffer is associated with a descriptor, a buffer head.
$include/linux/buffer_head.h struct buffer_head { unsigned long b_state; // buffer status flags struct buffer_head *b_this_page; // per-page buffer list struct page *b_page; // pointer to the descriptor for the page that stores the buffer sector_t b_blocknr; // logical block number size_t b_size; // block size char *b_data; // pointer to buffer atomic_t b_count; // use count /* etc */ };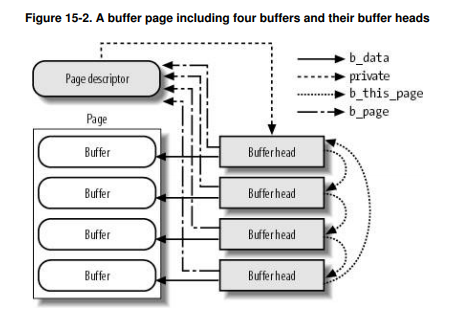
- b_count
- the buffer's usage count
- Before manipulating a buffer head, you must increment its reference count via get_bh() to ensure that the buffer head is not allocated out from under you.
- When finished with the buffer head, decrement the reference count via put_bh().
$include/linux/buffer_head.h static inline void get_bh(struct buffer_head *bh) { atomic_inc(&bh->b_count); } static inline void put_bh(struct buffer_head *bh) { atomic_dec(&bh->b_count); }
- b_count
- Before the 2.6 kernel, the buffer head was used as the unit of I/O in the kernel.
- Not only did the buffer head describe the disk-block-to-physical-page mapping, but it also acted as the container used for all block I/O.
- problem
- The buffer head was a large and unwieldy data structure, and it was neither clean nor simple t manipulate data in terms of buffer heads.
- In the 2.6 kernel, much work has gone into making the kernel work directly with pages and address spaces instead of buffers.
- address_space structure, pdflush daemons
- The buffer head describes only a single buffer.
- The primary goal of the 2.5 development kernel was to introduce a new flexible, and lightweight container for block I/O operations.
- bio structure
- The buffer head was a large and unwieldy data structure, and it was neither clean nor simple t manipulate data in terms of buffer heads.
The bio structure
$include/linux/blk_types.h
struct bio;
$include/linux/bvec.h
struct bio_vec {
/* pointer to the physical page on which this buffer resides */
struct page *bv_page;
/* the length in bytes of this buffer */
unsigned int bv_len;
/* the byte offset within the page where the buffer resides */
unsigned int bv_offset;
};
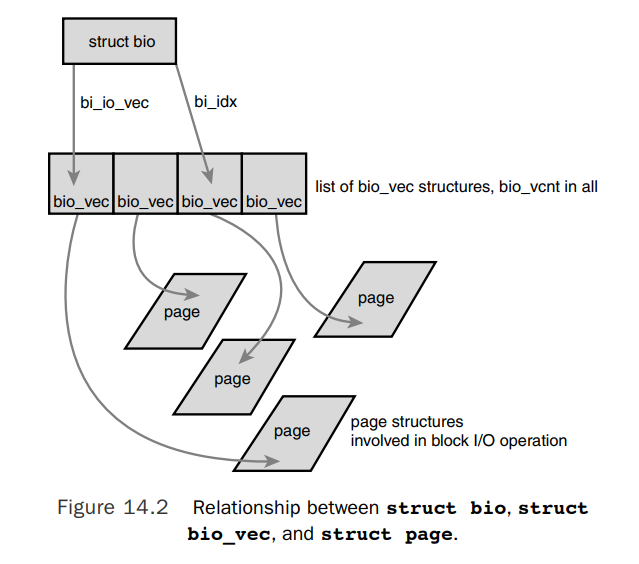
- The basic container for block I/O within the kernel is the bio structure.
- The primary purpose of a bio structure is to represent an in-flight I/O operation.
- The bio structure provides the capability for the kernel to perform block I/O operations of even a single buffer from multiple locations in memory.
Request Queues
$include/linux/blkdev.h
struct request;
struct request_queue;
- Block devices maintain request queues to store their pending block I/O requests, request_queue structure.
- The request queue contains a doubly linked list of requests and associated control information.
- Each item in the queue's request list is a single request, of type struct request.
- Each request can be composed of more than one bio structure.
I/O Schedulers
The Job of an I/O Scheduler
- An I/O scheduler works by managing a block device's request queue.
- It manages the request queue with the goal of reducing seek time, which results in greater global throughput.
- I/O schedulers perform two primary actions to minimize seek time: merging and sorting.
- merging : If a request is already in the queue to read from an adjacent sector on the disk, the two request can be merged into a single request operating on one or more adjacent on-disk sectors.
- sorting : The entire request queue is kept sorted, sectorwise, so that all seeking activity along the queue moves sequentially over the sectors of the hard disk.
The Linus Elevator
$block/elevator.c
- properties
- If a request to an adjacent on-disk sector is in the queue, the existing request and the new request merge into a single request.
- If a request in the queue is sufficiently old, the new request is inserted at the tail of the queue to prevent starvation of the other, older, requests.
- If a suitable location sector-wise is in the queue, the new request is inserted there. This keeps the queue sorted physical location on disk.
- Finally, if no such suitable insertion point exists, the request is inserted at the tail of the queue.
- The Linus Elevator could provide better overall throughput via a greater minimization of seeks if it always inserted requests into the queue sector-wise and never checked for old requests and reverted to insertion at the tail of the queue.
- starvation
- Heavy disk I/O operations to one area of the disk can indefinitely starve request operations to another part of the disk.
- Indeed, a stream of requests to the same area of the disk can result in other far-off requests never being serviced. This starvation is unfair.
The Deadline I/O Scheduler
$block/deadline-iosched.c
- properties
- When a new request is submitted to the sorted queue, the Deadline I/O scheduler performs merging and insertion like the Linus Elevator.
- Deadline I/O scheduler also, however, inserts the request into a second queue that depends on the type of request, read FIFO and write FIFO.
- Under normal operation, the Deadline I/O scheduler pulls requests from the head of the sorted queue into the dispatch queue.
- If the request at the head of either the write FIFO queue or the read FIFO queue expires, the Deadline I/O scheduler then begins servicing requests from the FIFO queue.
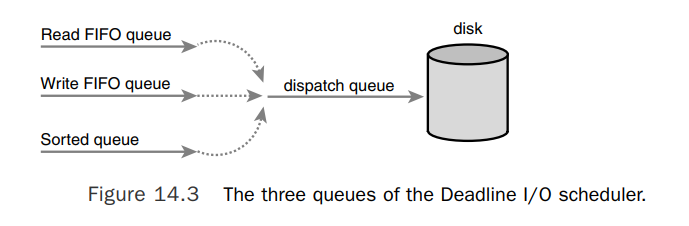
- The Deadline I/O scheduler works harder to limit starvation while still providing good global throughput.
The Anticipatory I/O Scheduler
- properties
- After the request is submitted, the Anticipatory I/O scheduler does not immediately seek back and return to handling other requests.
- Instead, it does absolutely nothing for a few milliseconds. In those few milliseconds, there is a good chance that the application will submit another read request.
- After the waiting period elapses, the Anticipatory I/O scheduler seeks back to where if left off and continues handling the previous requests.
- The Anticipatory I/O scheduler attempts to minimize the seek storm that accompanies read requests issued during other disk I/O activity.
- With a sufficiently high percentage of correct anticipations, the Anticipatory I/O scheduler can greatly reduce the penalty of seeking to service read requests, while still providing the attention to such requests that system response requires.
The Complete Fair Queuing I/O Scheduler
$block/cfq-iosched.c
- properties
- There is one queue for each process submitting I/O.
- The CFQ I/O scheduler services the queues round robin, plucking a configurable number of requests from each queue before continuing on to the next.
- The CFQ I/O scheduler is an I/O scheduler designed for specialized workloads, but that in practice actually provides good performance across multiple workloads.
The Noop I/O Scheduler
$block/noop-iosched.c
- properties
- The Noop I/O scheduler does not perform sorting or any other form of seek-prevention whatsoever.
- The Noop I/O scheduler does perform merging as its lone chore.
- The Noop I/O scheduler is intended for block devices that are truly random-access, such as flash memory cards.
- If a block device has little or no overhead associated with "seeking", then there is no need for insertion sorting of incoming request, and the Noop I/O scheduler is the ideal candidate.