16. The Page Cache and Page Writeback
리눅스 커널은 디스크의 데이터를 캐싱하는데, 이를 페이지 캐시(page cache)라고 하고, 캐시되어 있던 페이지가 다시 디스크로 적용되는 것(동기화 되는 것)을 page writeback이라고 한다. 페이지 캐시의 최대 목적은 디스크 입출력을 최소화 시키는 데 있다.
- 디스크 접근은 메모리 접근에 비해 상대적으로 많이 느리다. milliseconds vs nanoseconds
- L1 > L2 > L3 > Memory > Disk
- Data Locality: 최근에 사용된 데이터는 다시 사용될 가능성이 높다.
Approaches to Caching
RAM의 물리적인 페이지로 이루어져 있는 페이지 캐시는, 디스크의 블록과 대응된다.
페이지 캐시의 사이즈는 동적이다. 여유 공간(free memory)이 있을 때엔 최대한으로 페이지 캐시를 사용할 수 있고, 그러지 않은 경우(memory pressure)에는 최소한으로 수축할 수도 있다. 현재 캐싱 되어있는 스토리지를 backing store라고 부르는데, 이는 캐시 데이터 뒤에서 존재하면서 데이터의 원형을 저장하고 있기 때문이다.
디스크 접근 연산이 수행될 때마다, 가장 처음으로 데이터를 찾는 곳이 바로 페이지 캐시이다. 예를 들어 어떤 유저 프로세스가 디스크의 데이터를 읽는 시스템 콜을 호출했다고 하자.
read()시스템 콜 호출- 페이지 캐시에 원하는 영역의 데이터가 있는지 확인
- 만약에 있다면? (== cache hit) RAM에서 데이터를 바로 읽어간다.
- 만약에 없다면? (== cache miss) 커널은 디스크로부터 데이터를 읽어오기 위해 블록 I/O 연산을 스케줄링 해야한다.
Write Caching
디스크에 데이터를 쓰려고 할 때 write() 시스템 콜을 이용한다. 이 때, 총 3가지 동작을 예상할 수 있다.
write()에 대해서 이미 캐싱해놓은 데이터와는 상관없이 바로 디스크에 데이터를 내려버리는 경우.즉, 메모리에 있는 캐시 데이터를 지나치고 바로 디스크로 데이터를 갱신한다.
이 경우에는 기존에 캐싱되어 있는 페이지 캐시는 invalidate 된다. 만약
read()가 해당 데이터에 대해서 들어오면 디스크로부터 읽어온다.메모리에 있는 캐시와 디스크 모두 갱신해준다. 가장 간단한 방법으로 이러한 방식을 *write-through cache라고 한다. 캐시부터 디스크까지 모두
write()연산이 수행된다. 이 경우 캐시와 디스크 모두를 항상 최신 상태로 만들어주기 때문에 캐시를 일관성있게 유지해준다. (*cache coherent)(현재 Linux에서 사용하고 있는 방식) write back 방식은
write()요청이 들어왔을 때 페이지 캐시에만 우선 갱신하고 backing store에는 바로 갱신하지 않는 방식이다. 이 방식을 채택하면 cache와 원본 데이터가 서로 다르게 되며, 캐시에 있는 데이터가 최신 데이터가 된다. 최신 데이터는 캐싱이 된 이후로 업데이트가 되었다는 의미로 dirty 상태(unsynchronized)가 되며 dirty list에 추가되어 커널에 의해 관리된다. 커널은 주기적으로 dirty list에 등록되어 있는 페이지 캐시를 backing store에 동기화해주는데 이러한 작업을 writeback이라고 한다. writeback 방식은 write-through 방식보다 나은 방법인데, 왜냐하면 최대한 디스크에 쓰는 것을 미루어둠으로써 나중에 대량으로 병합해서 디스크에 쓸 수 있기 때문이다. 단점은 조금 더 복잡하다는 것이다.
Cache Eviction
캐싱 되어있는 페이지는 더 높은 연관성을 가진 페이지 캐시로 교체 되기 위해 내려가거나, 혹은 메모리 공간을 다른 이유로 확보하기 위해 내려가야하는 경우가 생긴다. 이처럼 "무엇을 내릴 것인가"를 결정하는 의사선택을 cache eviction이라고 한다.
현재 리눅스에서는 clean 페이지를 선택하여 다른 것으로 바꾸고 있다. 예를 들어 메모리 공간이 더 필요하다는 판단이 섰을 때, 커널은 clean 페이지들을 충분한 메모리 공간을 얻을 때까지 디스크로 writeback한다. 그렇다면 clean 페이지들 중에서는 어떤 페이지를 내리는 것이 현명한 선택일까? 바로 가까운 미래에 가장 사용되지 않을 것 같은 페이지를 찾아 내리는 것이 가장 현명한 방법일 것이다. (clairvoyant algorithm, 이상적이나 실현가능하지는 않은)
Least Recently Used
clarivoyant algorithm은 이상적이지만 실현가능하지 않기 때문에 가장 근접한 방식의 유사 알고리즘을 이용한다. LRU(Least Recently Used) 알고리즘은 가장 최근에 사용되지 않은 페이지를 교체한다. 이를 위해 모든 페이지들은 '시간 정보(time stamp)'를 가지고 있어야하며 LRU 알고리즘은 그 시간정보를 이용하여 가장 오래된 페이지부터 교체한다.
The Two-List Strategy
리눅스는 2개의 리스트(active list + inactive list)를 이용하여 LRU 알고리즘을 구현하고 있다.
Active list: 이 리스트는 자주 참조되어 "hot"하다고 여겨지는 페이지들의 공간이다. 교체 후보에서 제외된다.
active list에 들어오려면 먼저 inactive list를 거쳐 들어와야 한다.
Inactive list: 교체될 여지가 있는 후보들이 모여있는 공간이다.
두 리스트의 노드들은 마치 큐와 같이 모두 tail에 추가 되고 head에서 제거된다. 두 리스트는 균형을 계속 맞추게 되는데, 만약 active list의 크기가 inactive list의 크기보다 커지면 active list가 가리키고 있는 head를 inactive list로 넘겨준다.
이렇게 2개의 리스트를 이용하여 페이지들을 관리하면 the only-used-once failure를 간단하게 해결할 수 있다.
The Linux Page Cache
페이지 캐시는 일반적인 파일시스템의 파일, 블락 디바이스의 파일, 그리고 메모리 매핑이 되어있는 파일들로부터 메모리 상으로 캐싱되어 있는 페이지를 말한다. 같은 맥락으로, 페이지 캐시는 최근에 접근했던 파일의 일부를 담고 있다. 페이지를 읽거나 쓰는 입출력 연산이 수행될 때, 커널은 읽거나 쓰려고하는 대상 데이터가 캐싱된 페이지들 중 하나에 있는지 확인한다. 만약 있다면 빠르게 메모리로부터 요청을 수행해줄 것이요 그렇지 않다면 디스크로 다녀와야하는 수고로움을 겪게 된다.
The address_space Object
캐싱되어있는 페이지는 여러 연속적이지 않은 물리적 디스크 블락들의 복사본으로 이루어져있을 수 있다. 페이지 캐시에 규격화된 구조 없이 데이터가 산개해 있는 이러한 구조는 실제로 어떤 데이터가 캐싱되어 있는지를 찾는 과정을 매우 복잡하게 만든다. 디바이스의 이름과 블락 번호만 있으면 (이론적으로는) 해당 데이터가 어떤 페이지 캐시에 있는지 찾을 수 있어야하는데, 실제로는 앞선 문제로 인해 어렵다.
사실 페이지 캐시는 파일 시스템 데이터만을 위한 캐시였다. 그러나 현재 리눅스의 페이지 캐시는 다양한 용도의 페이지들을 캐싱할 수 있다. 즉 리눅스의 페이지 캐시는 상당히 일반적인 용도로 사용된다. 리눅스 페이지 캐시는 페이지 기반 오브젝트라면 캐싱할 수 있는 구조를 목표로 하고 있다.
inode structure를 확장시켜 페이지 I/O를 지원하게 함으로써 리눅스에서 페이지 캐싱이 가능하다 하더라도, 페이지 캐시를 파일에 국한시켜 생각할 수밖에 없다. 이런 일반화된 페이지 캐시(generic page cache) ㅡ 물리적으로 파일 혹은 아이노드와 묶이지 않는 ㅡ 를 구현(유지)하기 위해서는 새로운 객체를 도입할 수 밖에 없다. address_space구조체가 바로 그것이다. == page_cache_entity, physical_pages_of_a_file
15장에서 다루었던 vm_area_struct가 실제 하나의 파일의 여러 표현들이라면, address_space는 실제 그 파일 데이터의 물리 공간을 표현하는 구조체이다.
![\includegraphics[width=15cm]{graphs/process.ps}](http://rus-linux.net/MyLDP/BOOKS/VirtMem/img21.png)
i_mmap 필드는 priority search tree (a clever mix of heaps and radix trees) 자료구조를 사용하며 해당 주소 공간에 맺어진 모든 shared와 private mapping을 관리한다. address_space 구조체와 vm_area_struct 구조체는 물리 페이지 - 가상 페이지의 관계로, 1:다 매핑이 맺어질 수 있다.
address_sapce 구조체는 커널의 몇몇 객체들과 연관되어 있을 수 있는데, 보통은 아이노드와 매핑이 되어 있고 그럴 때에는 호스트 필드가 연결되어있는 아이노드를 가리키고 있다. 만약 호스트 필드가 아이노드가 NULL이라면 아이노드와 연결되어 있는 것이 아니라 다른 객체 (예를들면 스와퍼)와 연결되어 있을 수 있다.
address_space Operations
a_ops 는 함수 포인터의 모음집(구조체) adress_space_operations 을 매핑하고 있어서 address_space와 관련된 함수들을 모두 가지고 있다. 이 함수 포인터들은 해당 캐시 객체와 관련된 페이지 I/O들을 구현하고 있다. 각 backing store(filesystem)들마다 구현이 다를 수 있으므로 파일시스템들이 원하는 대로 구현할 수 있도록 인터페이스 역할을 한다.
페이지를 읽거나 쓰고, 캐싱하고, 캐싱된 데이터를 수정하는 등 페이지 및 페이지 캐시와 관련된 일련의 모든 수행들을 관리하는 구조체이다. 당연히 readpage()와 writepage() 메소드가 가장 중요하다. :)
find_get_page(): 데이터가 페이지 캐시에 있는지 확인할 때 사용됨, address_space 구조체와 페이지 offset 값 이용- 찾으면 해당 페이지를 돌려주고 못 찾으면 NULL 반환과 함께 새로운 페이지가 할당되어 페이지 캐시에 등록된다.
Radix Tree
페이지 I/O 요청이 들어왔을 때 해당 페이지가 존재하는 지를 페이지 캐시에서 빠르게 확인해야할 필요가 있다. 페이지 캐시를 찾는 일은 address_space 객체와 offset 값을 가지고 찾는데, address_space 객체는 각자 고유한 radix 트리(이진 트리의 일종)를 가지고 있어서 offset 값을 이용해 검색을 빠르게 해준다.
find_get_page()radix_tree_lookup()
The Old Page Hash Table
커널 버전 2.6 이전에는 radix tree가 아닌 전역 hash를 이용하여 전체 페이지들을 관리했었다. 그러나 총 4가지 큰 문제점이 있었다.
- global 해시를 묶는 coarse grained lock의 컨텐션
- 페이지 캐시에 존재하는 모든 페이지들을 관리하다 보니 한 파일의 입장에서 본다면 관련된 페이지만 있었으면 좋겠지만 그렇지 않고 필요 이상의 크기를 가짐
- 생각보다 성능이 좋지 않더라.(해시 체인 따라가서 찾는 비용이 비싸다.)
- 해시의 근본적인 메모리 문제
The Buffer Cache
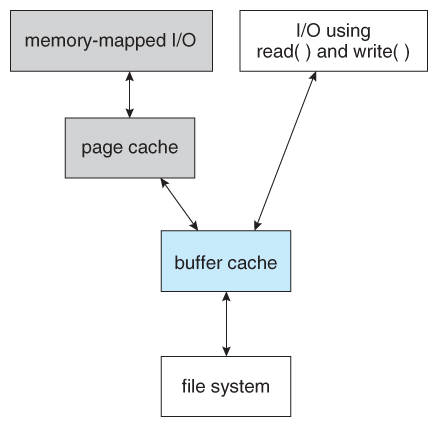
블락 I/O 버퍼를 이용하여 디스크 블락들이 페이지 캐시에 묶일 수 있다. 14장에서 다루었 듯, 버퍼는 물리 디스크 블락의 in-memory 복사본(representation)이다. 이러한 버퍼들은 디스크 블락과 메모리를 매핑하고 있으므로 매핑 페이지처럼 활용된다. 따라서 페이지 캐시는 디스크 블록을 캐싱하고 나중에 블록 입출력 작업을 버퍼링하여 블록 입출력 작업 중에 디스크 액세스를 줄이는 역할을 해준다. 이러한 캐싱을 버퍼 캐시라고 하며 페이지 캐시의 부분적인 역할이라고 생각하면 된다.

inode를 쓰거나 읽는 일이 가장 흔한 블락 I/O 명령이라고 할 수 있는데, 이러한 블락 I/O 명령은 한 번에 하나의 디스크 블락을 조작한다. 커널은 bread()함수를 이용하여 디스크로부터 하나의 블락을 읽어온다. 버퍼를 이용한다면 읽어온 이 디스크 블락을 연관있는 in-memory 페이지에 맵핑을 하고, 페이지 캐시로서 캐싱을 해둔다.
2.4 버전 이전에는 페이지 캐시를 이용한 버퍼 캐싱이 분리되어 있었다. 즉 페이지 캐시 따로 버퍼 캐시 따로 존재하였다. 그러나 이런 구조는 두 캐시 카피들을 모두 동기화해줘야하는 번거롭고 불필요한 작업을 요구하기 때문에 현재는 페이지 캐시라는 하나의 디스크 캐시만을 가지고 있다. 그러나 커널은 버퍼가 여전히 필요하므로 페이지 캐시를 이용하여 버퍼링을 하고 있다.
The Flusher Threads
디바이스에 데이터를 쓰는 write() 명령은 페이지 캐시 때문에 실제 작업이 뒤로 미루어진다. 만약에 페이지 캐시에 있는 데이터가 실제 backing store보다 더 최신이라면 해당 데이터는(페이지는) dirty한 상태가 되고, 이 dirty 페이지는 수정 사항들이 누적되다가 결국에는 다시 스토리지에 쓰여져야한다. 그리고 그 writeback과정은 아래와 같은 3가지 시나리오로 일어나게 된다.
- 여유 공간이 많이 줄어들어서 특정한 threshold에 도달하게 되면 커널은 dirty 데이터를 디스크로 내린다. 왜냐하면 여유 공간을 할당하기 위해서 page eviction을 수행해야 하는데, page eviction의 victim은 clean page밖에 없기 때문에 dirty page들을 clean page로 바꾸어주어야 한다.
- 만약 dirty 데이터가 충분히 오랜 시간동안 dirty한 상태를 유지한다면 무기한 dirty한 상태로 둘 수 없으므로 특정 임계치를 넘어갈 때 디스크로 내려준다.
- 유저 프로세스가
sync()혹은fsync()와 같은 시스템 콜을 호출하면 요청에 의해 커널이 writeback을 수행한다.
writeback작업을 해주는 커널 쓰레드를 flusher thread라고 한다.
Laptop Mode
배터리 소모를 최적화하기 위해서 리눅스에서는 laptop mode가 있다.
History: bdflush, kupdated, and pdflush
2.6 버전 이전에 사용되었던 flush daemon들