Chapter 12 - Memory Management
Memory allocation inside the kernel is not as easy as outside the kernel
커널 내부의 메모리 할당 방법 소개
Pages
- 메모리 관리의 기본단위
- page size는 architecture dependent + 여러 종류의 size 제공
- 모든 physical page들은 page 구조체로 관리
- 실제로 이것보다 더 많은 parameter가 존재하지만, 페이지 관리에 필수적인 인자들만 모아보면 다음과 같다.
/include/linux/mm_types.h
two word block size -> for atomic operating
struct page {
unsigned long flags; /* status of the page */
atomic_t _count; /* reference count */
atomic_t _mapcount; /* mapping count */
unsigned long private;
struct address_space *mapping;
pgoff_t index;
struct list_head lru;
void *virtual; /* virtual address */
};
Zones
비슷한 일을 하는 page들을 구역별로 나눠 놓은 것
Memory addressing의 한계 두 가지 >> Zone이 생긴 이유
- device의 DMA(Direct Memory Access)를 허용해야 함
- Virtual memory보다 Physical memory를 크게 잡아주는 경우가 생길 수 있음
일반적으로 다음과 같이 zone을 나누지만, 구역 설정은 architecture dependent하다.
ZONE_DMA,ZONE_DMA32- DMA가 가능한 구역 (0~16M)ZONE_NORMAL- default zone. 가장 일반적으로 할당받는 구역 (16M~896M)- 시스템에서 지원하는 물리메모리가 가상주소에 1:1로 mapping되어 사용할 수 있는 영역.
ZONE_HIGHMEM- high memory 구역. (896M~)- physical memory가 커널로의 virtual-physical의 1:1 mapping을 허용하는 구간을 초과하는 경우이다.
- 이 영역에서는 virtual-physical의 1:1 mapping이 되어있지 않고 physical memory만 할당되어있는 상태이다.
ZONE_NORMAL이 처리하지 못하는 경우 모두 이 영역에 할당된다.- 64bit 시스템에서는 모든 physical memory가 1:1 mapping이 가능하므로
ZONE_HIGHMEM을 사용하지 않는다. (ZONE_DMA와ZONE_NORMAL로만 구성)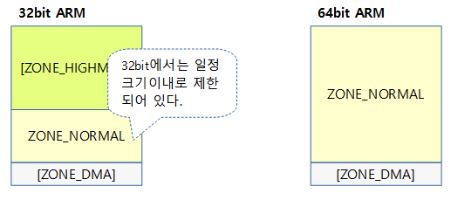
zone이라는 구조체를 통해 관리한다.
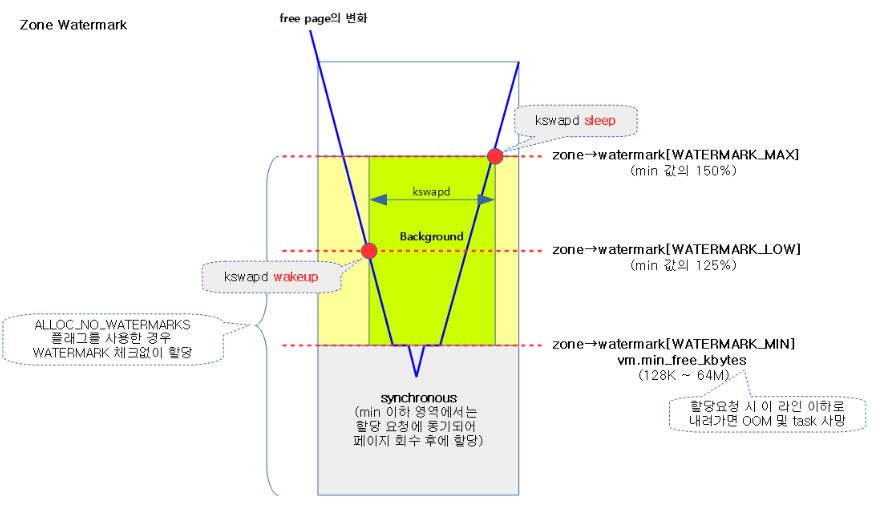
/include/linux/mmzone.h struct zone { unsigned long watermark[NR_WMARK]; unsigned long lowmem_reserve[MAX_NR_ZONES]; struct per_cpu_pageset pageset[NR_CPUS]; spinlock_t lock; /*protect struct from concurrent access*/ struct free_area free_area[MAX_ORDER]; spinlock_t lru_lock; struct zone_lru { struct list_head list; unsigned long nr_saved_scan; } lru[NR_LRU_LISTS]; struct zone_reclaim_stat reclaim_stat; unsigned long pages_scanned; unsigned long flags; atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS]; int prev_priority; unsigned int inactive_ratio; wait_queue_head_t *wait_table; unsigned long wait_table_hash_nr_entries; unsigned long wait_table_bits; struct pglist_data *zone_pgdat; unsigned long zone_start_pfn; unsigned long spanned_pages; unsigned long present_pages; const char *name; /*name of zone*/ };watermark는 메모리 소비에 따른 할당의 한계치를 표시한 것으로 다음과 같은 할당/회수관계를 갖는다.
Getting Pages
- 커널이 페이지 단위로 할당을 받고 싶을 때의 함수가 구현되어있다.
/include/linux/gfp.h
struct page* alloc_pages(gfp_t gfp_mask, unsigned int order) {
return alloc_pages_current(gfp_mask, order);
}
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order);
- NUMA 시스템일 경우 메모리 정책에 따라 노드를 선택하고 buddy 시스템을 통해 2^order 만큼의 연속된 페이지를 할당받는다
- NUMA 시스템이 아닐 경우 현재 노드에서 buddy 시스템을 통해 2^order 만큼의 연속된 페이지를 할당받는다.

page_address()를 통해 물리페이지가 가상메모리 어느 부분과 mapping되어있는지를 확인할 수 있다. 해당 페이지와 mapping된 가상메모리의 주소를 반환해준다.__get_free_pages(gfp_t gfp_mask, unsigned int order)는 alloc_pages와 같으나 HIGHMEM이 아닌 구역의 page를 할당해주고 할당 후 mapping된 가상메모리의 시작주소를 반환해준다./mm/page_alloc.c unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order) { struct page *page; VM_BUG_ON((gfp_mask & __GFP_HIGHMEM) != 0); page = alloc_pages(gfp_mask, order); if(!page) return 0; return (unsigned long) page_address(page); }만약 페이지 하나만 할당받고 싶을 때는
alloc_page(),__get_free_page()를 이용한다. oreder이 0으로 세팅되어있다.get_zeroed_pages()는__get_free_pages()를 한 후 모든 bit을 0으로 clear해준다.할당받은 페이지만 free해야 한다. 그렇지 않을 경우 치명적인 오동작을 일으킬 수 있다.
__free_pages(),free_pages(),free_page()함수를 이용한다.
kmalloc()
- 페이지보다 작은 단위(예를 들어, byte단위)로 메모리를 할당받고 싶을 때 사용한다.
/include/linux/slab.h
static __always_inline void *kmalloc(size_t size, gfp_t flags)
할당받은 공간의 제일 낮은 주소값을 반환한다.
유저공간의 메모리요청방식인
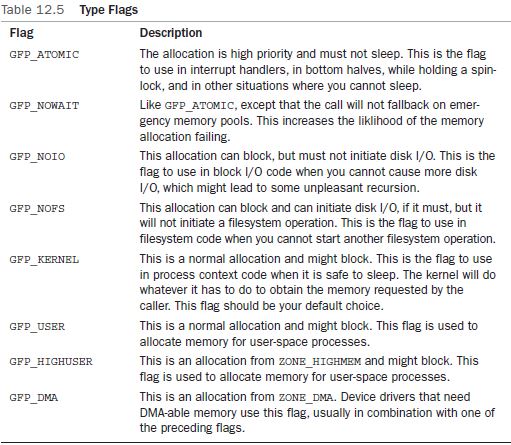
malloc()과 유사하지만, flag를 설정할 수 있다는 점에서 다르다.flag는 크게 세 가지 카테고리로 나누어져 있다.
action modifier - allocator이 어떤 특성을 가지고 동작할지를 설정할 수 있다.

zone modifier - 어느 구역의 공간을 할당해 줄 지를 설정할 수 있다.

types - action modifier와 zone modifier의 여러 flag들을 혼합해놓은 flag이다. 주로 여러 기능이 포함되어있는 이 flag를 사용한다.
- GFP_KERNEL이 가장 기본적인 flag이다.
- GFP_ATOMIC은 요청받은 할당을 atomic하게 수행해야 하기 때문에 sleep할 수 없다. 하지만 이는 메모리 부족시 swap을 위한 sleep도 막기 때문에 할당을 실패하기 쉽다.
kmalloc()을 이용해 메모리를 할당받은 경우만kfree()를 사용한다.
vmalloc()
kmalloc()은 연속된 메모리공간을 할당해주지만, 현실적으로 연속된 공간을 찾는 것이 쉽지 않다.vmalloc()은 가상메모리는 연속적이지만 물리메모리는 연속적이지 않아도 되는 할당요청이다.- 즉, 가상메모리공간의 16M-64M까지를 물리메모리와 mapping시키려 할 때, 물리메모리공간에서는 72M-120M처럼 연속적으로 할당할 필요 없이 메모리들의 파편들을 모아서 할당해줄 수 있다는 것이다.
- 하지만 필연적으로 page table을 만들어야한다는 성능상의 문제점 때문에 주로
kmalloc()을 사용한다. vfree()로 할당을 해제할 수 있다.
Slab Layer

- 자주 사용하는 메모리 크기를 미리 할당받아놓고 해당 크기의 요청이 들어오면 slab allocator이 미리 할당받아놓은 공간을 지급해주는 방식.
- free list가 가진 한계를 해결해 준 방식이다.
__alloc_pages_node()를 통해 새로운 slab을 만든다
/mm/slab.c
kmem_getpages() >> __alloc_pages_node()
static struct page *kmem_getpages(struct kmem_cache *cachep, gfp_t flags,
int nodeid) {
struct page *page;
int nr_pages;
flags |= cachep->allocflags;
if(cachep->flags & SLAB_RECLAIM_ACCOUNT)
flags |= __GFP_RECLAIMABLE;
page = __alloc_pages_node(nodeid, flags | __GFP_NOTRACK, cachep->gfproder);
if(!page) {
slab_out_of_memory(cachep, flags, nodeid);
return NULL;
}
....(후략)
}
kmem_cache_create()를 이용해 cache를 생성하고kmem_cache_destroy()를 이용해 제거한다.
Statically Allocating on the Stack
기존의 커널스택 할당 >> 연속된 두 페이지
컴퓨터의 동작시간이 길어질수록 '연속된' 두 페이지를 제공해주기가 매우 힘들어진다.
따라서 single-page kernel stack을 제공하는 옵션이 생김
- 연속된 페이지를 제공해야하는 어려움을 해결한 대신 커널스택의 여유가 줄어듦
- interrupt handler는 독자적인 interrupt stack을 만들어서 사용
High Memory Mappings
High memory구역에 있는 메모리들은 커널의 virtual(logical) address와 매핑이 되어있지 않은 상태
kmap()을 이용해 실제적으로 해제하기 전까지 영구적 mapping이 가능/include/linux/highmem.h -> mm/highmem.c kmap()->page_address() void *page_address(const struct page *page) { unsigned long flags; void *ret; struct page_address_slot *pas; if(!PageHighMem(page)) return lowmem_page_address(page); pas = page_slot(page); ret = NULL; spin_lock_irqsave(&pas->lock, flags); if(!list_empty(&pas->lh)) { struct page_address_map *pam; list_for_each_entry(pam, &pas->lh, list) { if(pam->page == page) { ret = pam->virtual; goto done; } } } done: spin_unlock_irqrestore(&pas->lock, flags); return ret; }- high memory, low memory 모두에 사용 가능
- low memory에 사용할 경우 이미 mapping이 되어있는 상태이므로 mapping된 virtual address를 반환
- high memory에 사용할 경우 virtual-physical mapping이 생성된 후 mapping된 virtual address를 반환
kunmap()을 이용해 mapping을 해제할 수 있다.
kmap_atomic()을 이용해 영구적 mapping이 아닌 일시적 mapping도 가능하다/include/linux/highmem.h static inline void *kmap_atomic(struct page *page) { preempt_disable(); pagefault_disable(); /* can't sleep through preemption or swap */ return page_address(page); } static inline void *kmap(struct page *page) { might_sleep(); return page_address(page); }- interrupt handler같은 sleep하지 않는 상황에서 사용한다.
- 오직 한 page의 virtual-physical mapping만 잡고있을 수 있다.
kunmap_atomic()으로 mapping을 해제 할 수 있으나, 다음 temporary mapping이 들어오면 자동으로 기존 mapping이 해제되므로 잘 사용하지 않는다.
Per-CPU Allocations
SMP를 지원하는 OS는 per-CPU data를 이용한다.
per-CPU data는 각각의 core 자신만 볼 수 있는 data이다
- 4-core >> 4개의 per-CPU data
배열의 형식으로 저장된다.
core가 본인의 per-CPU data를 보는 데는 lock이 필요하지 않다. 각 core의 독자적인 data이기 때문에 다른 core에서 본인의 per-CPU data가 아닌 per-CPU data를 볼 수 없다.
- 2.6 이후 버전에서는 새로운 percpu interface를 소개한다
- 이 interface에서는 다른 core의 per-CPU data를 볼 수 있지만, 이 경우에는 concurrency 문제가 생길 수 있으므로 locking이 필요하다.
kernel preemption은 per-CPU data 사용에 있어서 2가지 문제를 발생시킨다.
- cpu0에서 per-CPU data를 이용한 작업을 하고 있던 task A가 reschedule되어 cpu1에서 재실행되는 경우
- cpu0에 preemption이 일어나 task B 또한 per-CPU data를 이용한 작업을 해 task A가 이용하던 data를 건드리는 경우
-- 이를 해결하기 위해 per-CPU data를 사용하는 경우, 즉
get_cpu_var()함수를 부르게 되면preempt_disable()이 일어나 kernel preemption을 막아버린다.
--put_cpu_var()를 이용해 per-CPU data 사용을 끝낼 때preempt_enable()해준다.compile-time에서는 다음 두 함수를 이용해 per-CPU data를 선언한다.
/include/linux/percpu-defs.h #define DEFINE_PER_CPU(type, name) \ DEFINE_PER_CPU_SECTION(type, name, "") #define DECLARE_PER_CPU(type, name) \ DECLARE_PER_CPU_SECTION(type, name, "") /* for avoid compile warning */